SRE 관련 정보 서칭중 당근 마켓 gRPC 관련 정보 공개 된게 있어 들어 보는 중에 정리합니다.

SRE팀을 만들때
총 3명이 있었고 3명이 구백만 천만 트래픽 MAU 기준으로
도메인 정리
네트워크 작업
클러스트 통합 작업 실시
당근마켓 내부 콜은 아래와 같다고 하고 마이크로서비스는 아래와 같다고 하네요.
처음 왔을때는 초당 1만 5천 정도였다고 하네요.

3월 15일날 직원수가 100명일때 아래와 같은 상황이었다고합니다. 많타고 기념으로 찍어둔거라고 하네요.
초당 6만개 찍고 있고 직원도 2배가 되고 트래픽도 두개가 되었다고 합니다.

플랫폼 위주로 안정적 서비스가 되니 인증 및 이미지 서버들이 제공되니 MSA 서비스에서 이 플랫폼을 사용하는 요청이 늘어나게 되었고
이를 잘 적은 인원으로 잘 운용을 할려면 어떻게 해야 할지 고민함.
아래와 같이 레버지를 잘 사용하자 오픈 소스를 잘 활용하자 라고 생각 한듯 하네요.
엔진 엑스 프록시 서버 쿠버네티스 이스티오 등등 이걸 사용한 트래픽 이동을 준비 실시하마.
이스티오 및 머신 러닝을 사내 매직 워드로 이스티오를 활용하고 잘 쓰고 있습니다.

SRE로서 트래픽의 흐름을 모니터링 및 이해를 해야 했고
아래것들 등 알아야 할께 많아야 하는데
SRE로서는 어떤 구간 어디서 문제가 발생 했는지 투명하게 서비스 디스커버리 / 문제를 파악해야 하는게 중요했습니다.
트래픽 플로우와 인프라 구조도를 그려야 했고 각 구간의 매트릭을 준비 해서
이슈 발생 구간을 빨리 파악 및 알아 내는것이었다고 합니다.

실제로 오퍼레이션도 많다고 하네요 가끔 MSA 서비스의 네트워크 이슈를 파악하기 위해 동일한 가진 테스트서버를 준비를 했고
아래 화면은 Go Lang으로 짠 테스트 서버 인데 go lang의 경우 go -debug를 활용하면 프레임레벨까지 로그가 나오는데
이런식으로 특정 프로덕션에 같은 환경을 공유 하는 테스트 서버를 두고 네트워크 디버깅을 했다고 하네요.

해당 테스트 서버에는 네트워크 분석에 필요한 CLI 도구를 말아서 넣고
필요하면 부하 발생 스크립트들도 마운트 해놓았고 등등 필요한 도구를 말어 넣어서 대응을 한거 같네요.

아래가 gRPC 인프라 구성이라고 합니다.
Active - Active
Active - Stand by 방식 보다는
쿠버네티스를 활용한 멀티 에이지에 떠 있어서 스위칭 방식을 활용함.

gRPC 에 대해서 ( gRPC 공식 블로그 체크가 필요하겠네요 )
MSA의 호출 방식을 개선 하기 위해서 몇 ms 라도 성능 향상을 통한 MSA 네트워크 통신의 이득을 취하기 위해
아래 gRPC를 검토하였다고 하네요.




채널이라는게 어플리케이션 개발자들이 상요하기 쉬움, 채널은 개발자들은 하나만 연결된걸로 보이겠지만.
인프라 측면에서는 여러가지를 연결 할수 있으므로 인프라적으로 체크를 할수 있는 장점이 있음.

gRPC 클라이언트가 똑똑하다고 하네요. 복원력이 좋나 보네요. 끓어졌다고 그냥 끓어 지는걸로 끝나지 않토록 만들어졌나 부네요.
아마 인프라 네트워크 레벨에서 전보다는 긇어졌을경우 클라이언트가 별도의 복원을 위한 기능이 있나 본데 확인이 필요하겠네요.

커넥션이 닫히는것과 채널을 닫는것은 다른것임. 채널은 닫지 않으면 계속 유지되고 커넥션은 끓어지면 클로즈하고 다시 연결하기 위한 시도가 자동으로 이루어 진다 순단은 있을수 있나 보네요.
와이어 샤크로 패킷 핸드세이킹 하는 모습을 보여 주셔먼 설명을 해주시네요. .추천한다고 합니다. ^^


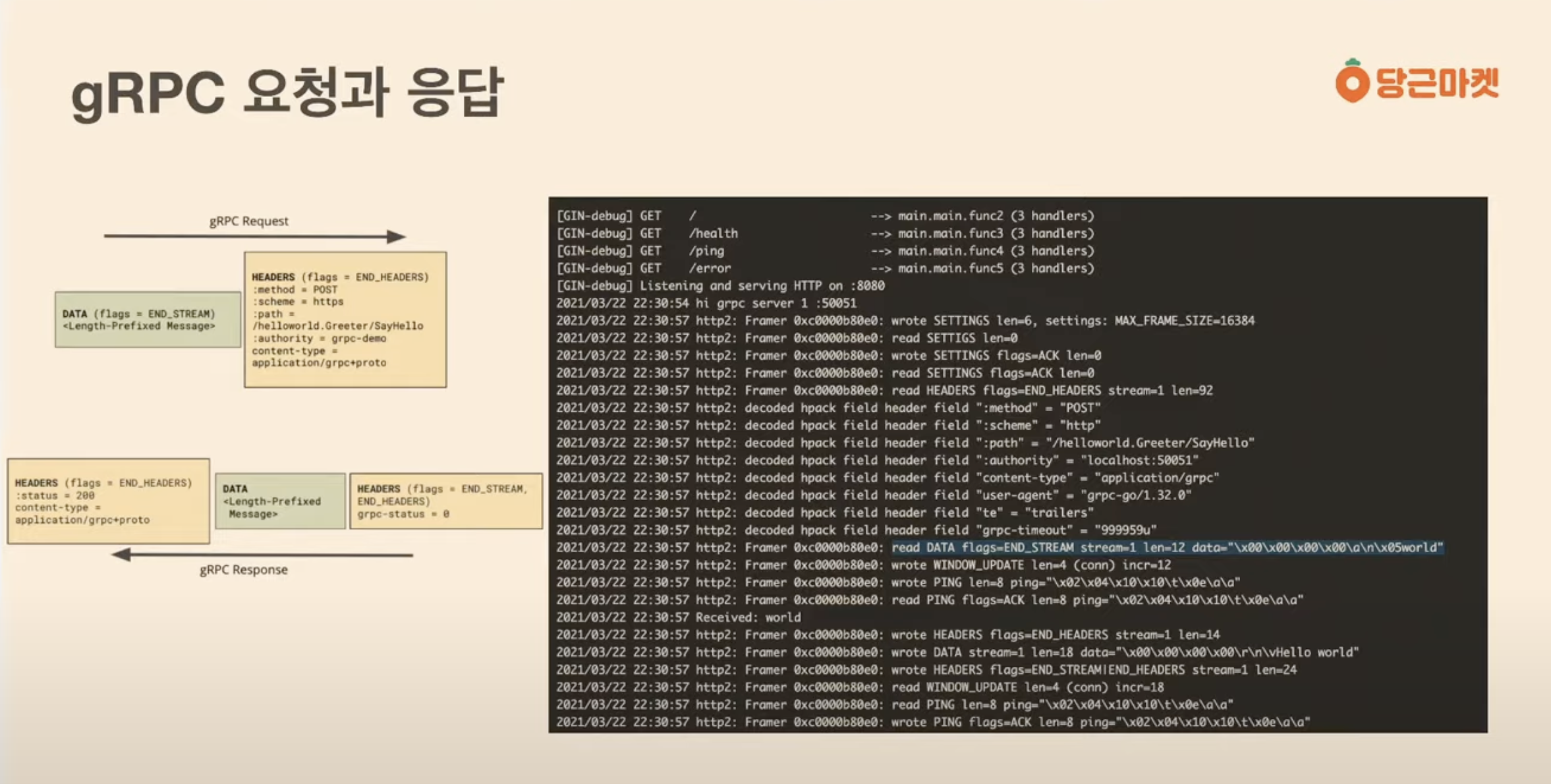


해더와 바디의 정보가 응답과 요청이 잘 오고 갔는지 디버징을 잘하면 해당 포인트의 문제점 파악을 잘 할수 있을것이다라며
메세지들이 gRPC에서 어떻게 흘러가는지를 설명하면서 실제 구조가 CLI에 어떻게 찍히는지 설명을 해주시고 계시네요.
어플리케이션 Status CODE와
인프라 Status CODE가 다르게 잘 분리 되어 있음. 이전에는 해당 코드들이 일부 논란의 소지가 인프라와 어플리케이션간에 있었던
부분을 보완을 해놓아져 있다고 하네요.

아래 부분에 논란의 소지 영역을 안내해주시네요.

SRE쪽의 역활이 여기서 나오네요. 전반적인 인프라 관점에서 전역 쿼리로 에러가 튀는 서비스를 모니터링 한다는 관점이네요.
서비스에서 대시보드를 셋팅 할수 있도록 모니터링에 대한 제공 및 안내 지원을 해주고 있고
결국 개발 담당자 팀 및 담당자들 ( 즉 어플리케이션 MSA 서비스단 레이어)에서는 별도로 커스텀 대시보드를 셋팅하여
관리한다고 합니다.
VOC 측면에서는 글로벌 관점에서 서비스를 해야 하고 대규모 고객을 다루어야 한다고 하면
위와 같이 모니터링과 서비스 관리가 갈려서 관리하는게 효율적일지는 모르겠네요.
이부분은 각 서비스와 회사마다 상황과 고객수와 서비스의 중요도에 따라 투자와 인력 규모에 따라
조직은 달리 구성하여 가져 갈수 있는 부분이겠네요.


쿠버네티스 서비스가 L4로 구성되어 있다. 근데 필요한건 L7 이다. 인건지 쿠버네티스가 L4만 지원한다는건지? 확인이 좀 필요하겠군요.
스터디 필요


우리는 HAProxy 쓰다가 학을 땠는데.... 고객수가 많지 않을때는 문제가 안되었지만. 고객수가 급증 하고 나서는 이걸로 안된다고 결론을 내렸는데.. 당근이 아직 고객수의 트래픽이 많지 않은 영역에 대한 얘기 일까? 아니면 제대로 사용을 하지 못한걸까?
좀더 공부가 필요하겠네요. 일단 우리 경험에서는 HAProxy는 쓸게 못된다 개고생 한다 빼자, 하드웨어 레벨에서 고성능 LB로 처리하는걸로 선회를 했거든요. 100명 200명이 쓰는 정도면 문제가 전혀 안될꺼 같은데 이게 직원수인거고 사용자 고객 트래픽을 확인해봐야
이게 우리의 과거의 경험에 범위 안에서 쓰고 계신건지 아닌지 가늠을 할수 있겠네요.
과거 저희의 트래픽 수준이라고 하면 위 방식은 우리와 맞지 않을수 있겠네요. 우린 이미 경험하고 결론 짓고 떠난 지점이라
좀더 정보 수집과 비교가 필요한 구간이군요.
HAProxy 때문에 수많은 골치 아픈 장애를 경험했던터라 이후 H/W LB로 바꾸고 훨씬 나아져서
HAProxy라는 글자는 지금도 보면 경기가 나고 절대 쓰면 안될 기술로 ( 그때 기준으로 여전히 여파가 남아 있나 보네요 ) 생각하고있어서
왜 저걸 쓰지 하는 생각이 이 영상을 보는 순간 내내 머리에 멤돌아서 불편한걸 보면... 여전히 싫은가 봅니다.
언젠가 이것도 성능 향상이 엄청 이루어 지거나 이루어 졌다면 다시 들여다 봐야 할지도 모르겠네요.
당근 마켓 사용자수와 동접 트래픽이 얼마나 될려나??? 그걸 봐야 이 기술이 우리한테 효용성이 있는지 고려할 사항인지 판단해볼수 있겠군요.






개발자 중에 인간 모니터링들이 계시다 즉시 개발자 분들이 SRE 슬랙에 알림을 바로 바로 하시는 분들이 있다.
데이터 독 을 사용하고 있다고 하네요.
초기에 개발할때 커넥션 부분들과 리플렉션들을 넣어서 테스트 하고 점검하는 인프라 초기 셋팅 및 부하 테스트등이 중요합니다.
데이터독 Agent를 각 머신에 깔아서 트레이싱 용도로 사용중


gRPC 인프라 부하 테스트 스크립트들 제공. 혹시 모를 병목 구간 확인에 좋다고 하네요.

개발자 분들과 서로 돕고 일하는 환경이 중요함.
SRE 팀도 개발자 팀도 실수 할수 있다는 관점에서 이런걸 점검할수 있는 인프라 환경을 구성하고 사용할려고 합니다.


글로벌 동네 마켓으로 성장이 목표라고 하고 채용도 한다고 하네요.
작년 21년 8월 26일 공개된 내용이군요.
'프로그래머' 카테고리의 다른 글
| [당근마켓]당근 SRE 밋업 2회 - 쿠버네티스 멀티 클러스터에서 Addons 관리 (0) | 2022.01.27 |
|---|---|
| [당근마켓]당근 SRE 밋업 2회 - 배포시스템 유투브 영상 (0) | 2022.01.27 |
| 5. [VS Code]Flutter Test 앱을 만들어 iPhone에 배포하기 (0) | 2022.01.22 |
| 3. [IDE Install] Android Studio (0) | 2022.01.22 |
| 4. [IDE Install] VS Code (0) | 2022.01.22 |



